双调排序
Intro
排序类算子在大模型中有很多应用场景, 特别是TopK算子, 在Top-k / Top-p采样、MoE路由等发挥着重要的作用。
但是普通的排序算法在并行化上存在两个硬伤:
- 控制流密集:依赖比较 + 条件跳转,分支预测失败对性能的影响较大
- 数据依赖强:排序时每一层内部都依赖上一层结果
我们需要一个排序算法, 能够有尽可能少的层数, 层内尽可能少的分支跳转和尽可能多的并行化
GPGPU上是怎么做的?
采用Radix Sort/Select: 将待排序的 key 按位逐段处理, 每一轮取d位(常见d=4或8)作为digit, 对所有元素按该digit做一次稳定的分桶bucket. 不论输入的shape如何或者key之间的大小关系怎样, 只需要CEIL(32, d)轮即可完成排序
每一轮, 都做以下的操作:
- 分块与计算本地直方图: 把输入分散到16个bucket中
- 全局prefix scan: 计算每个bucket对应到全局的写入位置
- 全局Scatter: 根据前缀和把元素写回全局内存

NPU上是怎么做的?
采用Bitonic Sort
双调序列
理解 Bitonic Sort, 首先要理解什么是双调序列.
一个长度为 n 的序列 a₀, a₁, ..., aₙ₋₁ 若满足以下任一条件,则称为双调序列:
- 存在某个下标 k, 使得
a₀ ≤ a₁ ≤ ... ≤ aₖ ≥ aₖ₊₁ ≥ ... ≥ aₙ₋₁(先升后降) - 序列可以通过循环移位变成条件 1 的形式
直观地说,双调序列就是先单调递增再单调递减, 或者先单调递减再单调递增的序列, 纯粹的单调序列是双调序列的特例
核心引理
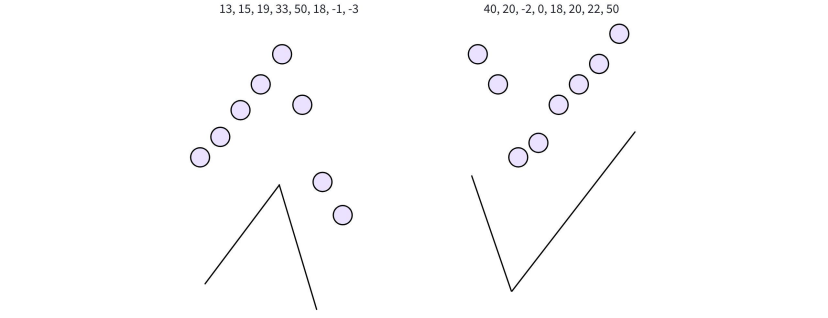
对于一个长度为 n (n 必须为 2 的幂) 的双调序列,执行如下操作:
将序列前后对折,对每一对元素 进行比较,较小者放到前半部分,较大者放到后半部分(也可以反过来), 经过这一步之后可以得到两个关键性质:
- 前半部分的所有元素都小于等于后半部分的所有元素 (若较大者在前半部分则是大于等于)
- 前半部分和后半部分各自仍然是双调序列
于是,排序一个双调序列的问题,被递归地拆解为排序两个规模减半的双调子序列的问题, 称为split
从双调排序到完整排序
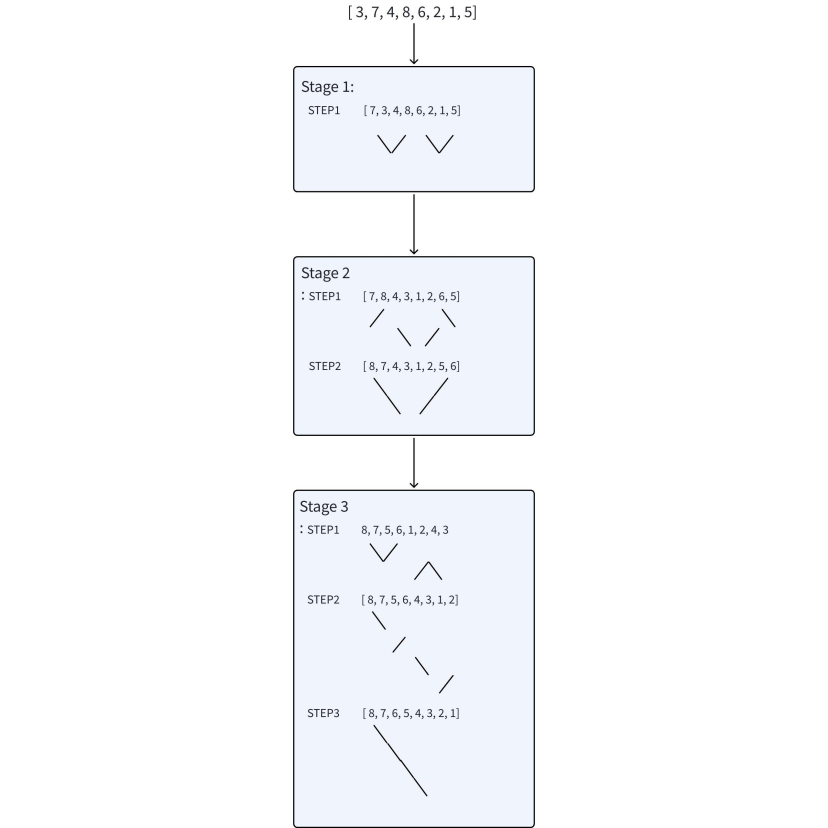
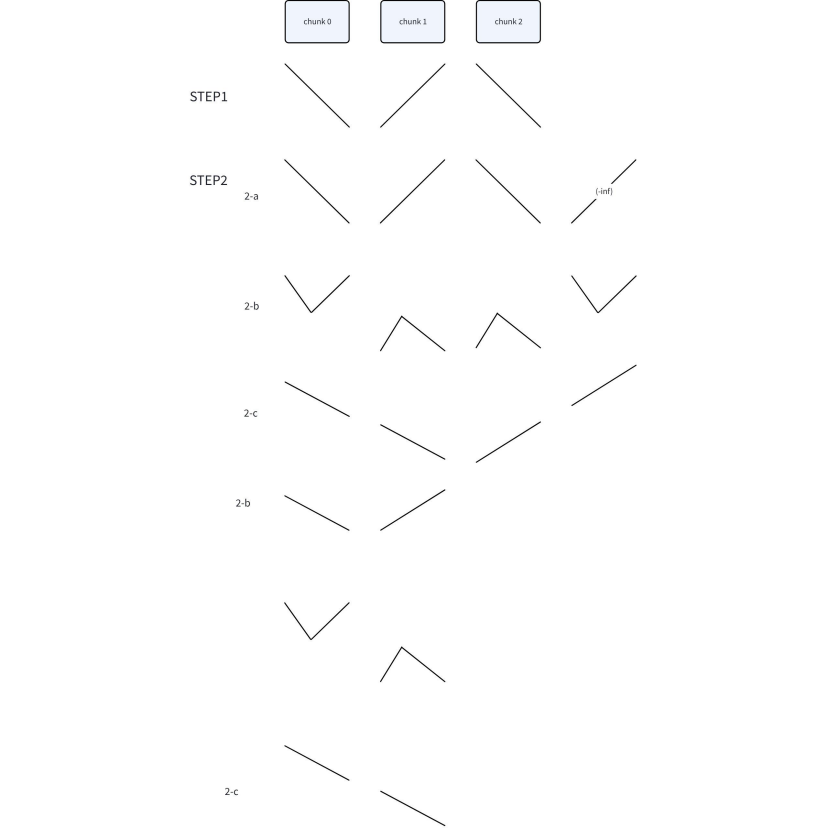
由于输入序列一般不会是天然的双调序列, 所以需要人为的自底向上构造, 需要多个Stage来不断扩大, 每个Stage分为多个Step
- Stage: 把若干个长度为的双调, 合并成长度为的有序段, 形成长度为的双调.
- Step: 对每一个长度为的双调序列执行一次split, 将其分裂为两个双调序列.
实现思路
同步一些特定名词:
block: 当前要排序的单调序列的长度, 等于当前stage开始时双调序列长度stride: 当前需要进行比较的两个元素的间隔, 一般小于等于blcok/2
核心思路
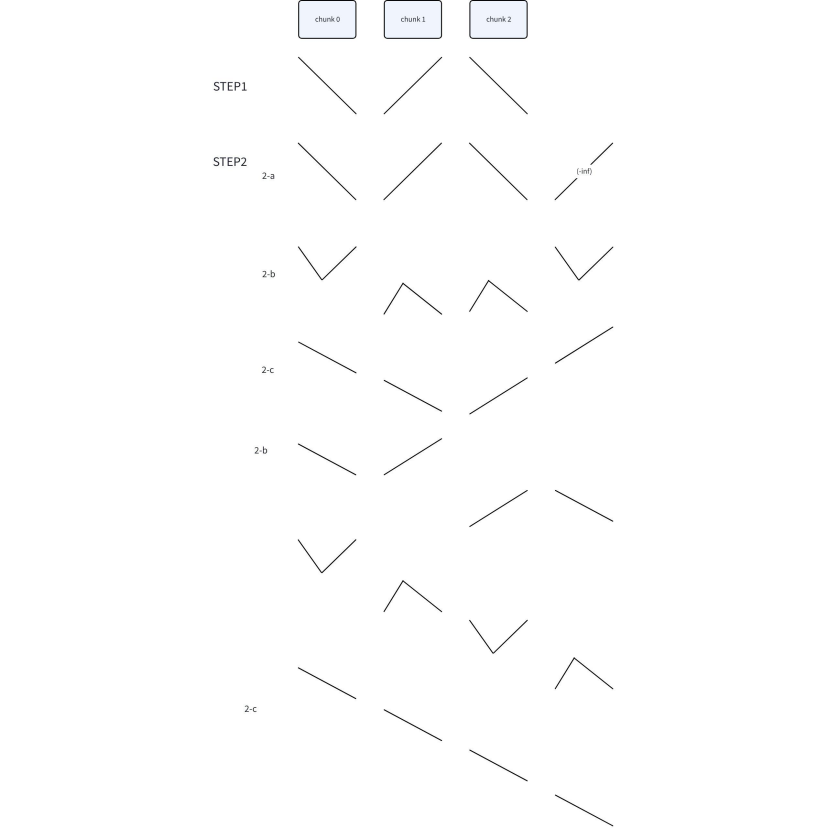
对于乱序的输入:
- 按照固定的
CHUNK_LEN, 将输入分为多个块, 对每个块直接调用排序kernel, 使每个块单调, 但是相邻的块单调性相反, 形成多个双调, 保存在SRAM上 - 如果块的数量为1, 则排序完成; 不为1则需要:
- 将块的数量padding到2的n次方, 根据整体的排序方向填充+inf / -inf
- 对于每个双调, 做split操作, 直至block大小等于
CHUNK_LEN - 把每个双调排为单调
- b和c两步会使相邻的双调按照不同的方向排序, 把双调序列的个数减半, block大小翻倍, 重复直至完全单调
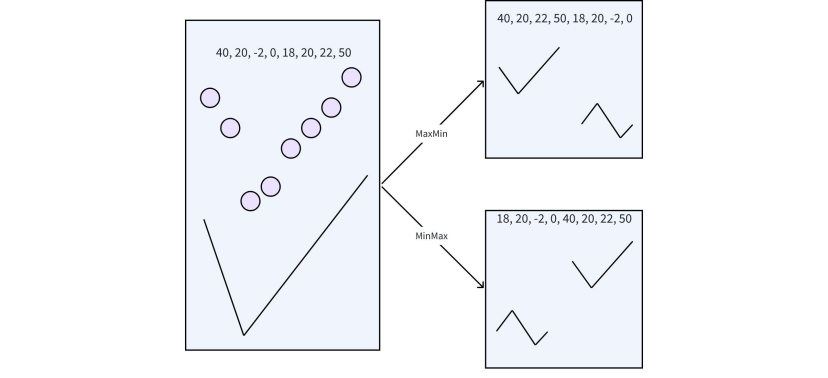
不难发现, 排序可以抽象为三种操作:
- 把完全无序的数据用tpc排成有序的, 称为
bitonic_sort, 这个过程受寄存器容量限制 - 把一个双调序列排成一个单调序列, 称为
bitonic_merge, 这个过程也受到寄存器容量限制 - 把一个双调序列分为两个单调序列, 称为
bitonic_split, 但是因为这个过程存在把大的数放到前半部分还是后半部分的问题, 为了简化就把大数在前称为maxmin, 反之minmax. 这个过程类似element-wise算子, 不需要一次性完成, 不受寄存器容量限制
TopK剪枝优化
TopK显然在大多数情况下不需要把整个输入序列都排好序, 所以进行剪枝对TopK的性能优化会有很大提升. 目前根据K的大小分为不同的剪枝方案
Small K
这里的small是指K可以在排序时保存在寄存器中, FP32/BF16下分别支持到最大4096/8192:
- 第一个chunk排序, 然后搬运到寄存器的TopK窗口内
- 之后的chunk排反序, 与窗口内的临时TopK形成双调
- 做split, 根据排序方向把较大的/较小的留在窗口内部, 其余丢弃
- 窗口内部的双调merge为一个单调
Large K
K更大, 在寄存器中放不下时, 就需要在SRAM中维护TOPK的窗口. 在原本排序的过程上, 如果已经能确定一个chunk内完全不包含TopK, 那么就可以将其丢弃
丢弃的过程一般发生在双调进行split时, 比较的败者不需要后续的处理, 只对胜者进行后续的merge
~刘博文 / Bowen Liu